Benchmarking the Robustness of Cross-view Geo-localization Models
European Conference on Computer Vision (ECCV)
Qingwang Zhang, Yingying Zhu *
Shenzhen University

Abstract
Cross-view geo-localization serves as a viable alternative to providing geographical location information when GPS signals are unstable or unavailable by matching ground images with geo-tagged aerial image databases. While significant progress has been made on some common benchmarks like CVUSA and CVACT, there remains a lack of comprehensive consideration for robustness against real-world environmental challenges such as adverse weather or sensor noise. This deficiency poses a significant challenge for deploying this technology in safetycritical domains like autonomous driving and robot navigation. To the best of our knowledge, there is currently no specialized benchmark for evaluating the robustness of cross-view geo-localization. To comprehensively and fairly evaluate the robustness of cross-view geo-localization models in real-world scenarios, we introduce 16 common types of data corruption. By synthesizing these corruptions on public datasets, we establish two fine-grained corruption robustness benchmarks (CVUSAC and CVACT_val-C) and three comprehensive corruption robustness benchmarks (CVUSA-C-ALL, CVACT_val-C-ALL, and CVACT_testC-ALL), covering approximately 1.5 million corrupted images. Subsequently, we conduct large-scale experiments on various cross-view geo-localization models to evaluate their robustness in corrupted environments and derive novel insights. Finally, we explore two data augmentation strategies as potential solutions to enhance model robustness. Combined with the training strategies proposed, these approaches effectively enhance the robustness of multiple models.
Figure 1: Existing cross-view geo-localization models fail when the ground query image is corrupted. When the query image is clean, almost all existing methods retrieve the ground truth correctly (marked by the red box and the red circle). Once the image is corrupted, almost all existing methods have missed the correct result. Incorrect retrieve and location results are marked in green and blue.

Figure 2: Various types and severities of common corruption in our robustness benchmarks, after cropping are provided.
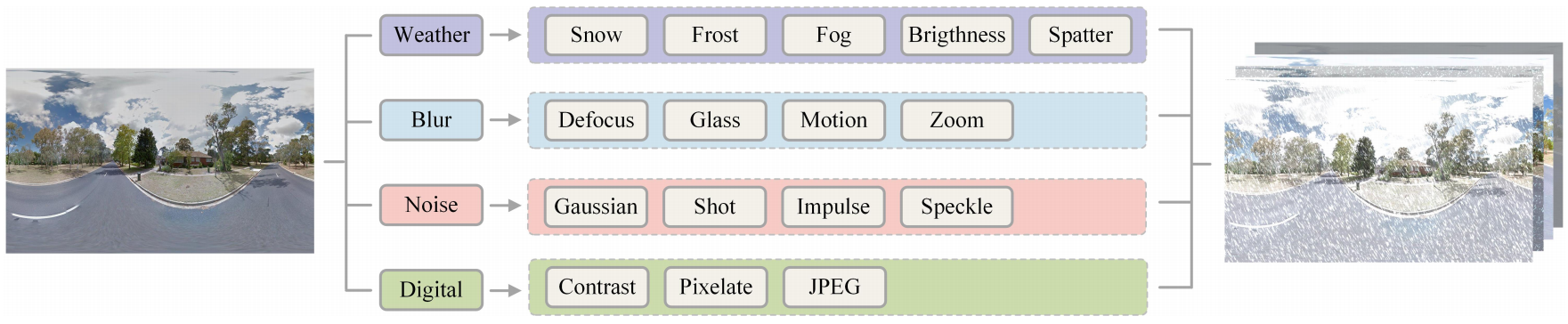
Figure 3: The proposed fine-grained and comprehensive robustness benchmarks. Each corruption category encompasses 5 severity levels. The primary distinction between fine-grained and comprehensive robustness benchmarks lies in whether separate evaluation subsets are created for each corruption category and severity level.

Figure 4: Visualization of Stylization/CLAHE applied to the CVUSA training set. The illustration depicts standard images (middle row), stylization images (top row), and CLAHE images (bottom row). The rounded rectangles on both sides represent different training strategies. The red dashed boxes indicate the style images sourced from https://www.kaggle.com/c/painter-by-numbers/.
Acknowledgement
This work was supported in part by the National Natural Science Foundation of China under Grant 62072318 and Grant U22A2079, in part by the Key Project of Department of Education of Guangdong Province under Grant 2023ZDZX1016, and in part by Shenzhen Science and Technology Program under Grant 20220810142553001.
Bibtex
@inproceedings{zhang2025benchmarking,
title={Benchmarking the Robustness of Cross-View Geo-Localization Models},
author={Zhang, Qingwang and Zhu, Yingying},
booktitle={European Conference on Computer Vision},
pages={36--53},
year={2025},
organization={Springer}
}
Downloads