SynFER: Towards Boosting Facial Expression Recognition with Synthetic Data
International Conference on Computer Vision (ICCV)
Xilin He1,6, Cheng Luo2, Xiaole Xian1, Bing Li2, Siyang Song4, Muhammad Haris Khan5,
Weicheng Xie1, Linlin Shen1, Zongyuan Ge3, Bernard Ghanem2, Xiangyu Yue6
1Shenzhen University 2KAUST 3Monash University
4University of Exeter 5MBZUAI 6Chinese University of Hong Kong
Abstract
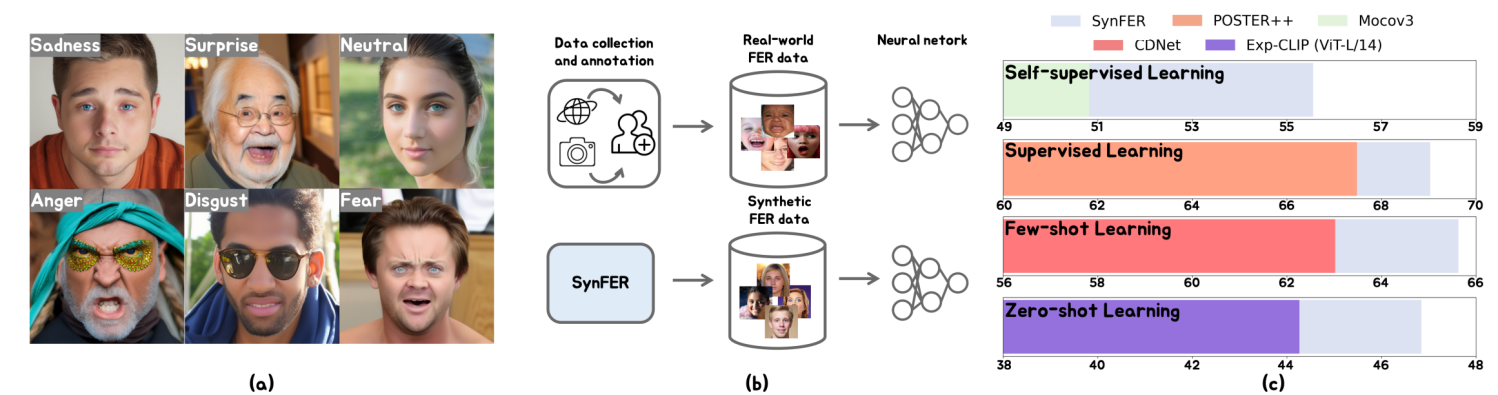
Facial expression datasets remain limited in scale due to the subjectivity of annotations and the labor-intensive nature of data collection. This limitation poses a significant challenge for developing modern deep learning-based facial expression analysis models, particularly foundation models, that rely on large-scale data for optimal performance. To tackle the overarching and complex challenge, instead of introducing a new large-scale dataset, we introduce SynFER (Synthesis of Facial Expressions with Refined Control), a novel synthetic framework for synthesizing facial expression image data based on high-level textual descriptions as well as more fine-grained and precise control through facial action units. To ensure the quality and reliability of the synthetic data, we propose a semantic guidance technique to steer the generation process and a pseudo-label generator to help rectify the facial expression labels for the synthetic images. To demonstrate the generation fidelity and the effectiveness of the synthetic data from SynFER, we conductextensive experiments on representation learning using both synthetic data and real-world data. Results validate the efficacy of our approach and the synthetic data. Notably, ourapproach achieves a 67.23% classification accuracy on AffectNet when training solely with synthetic data equivalentto the AffectNet training set size, which increases to 69.84%when scaling up to five times the original size.
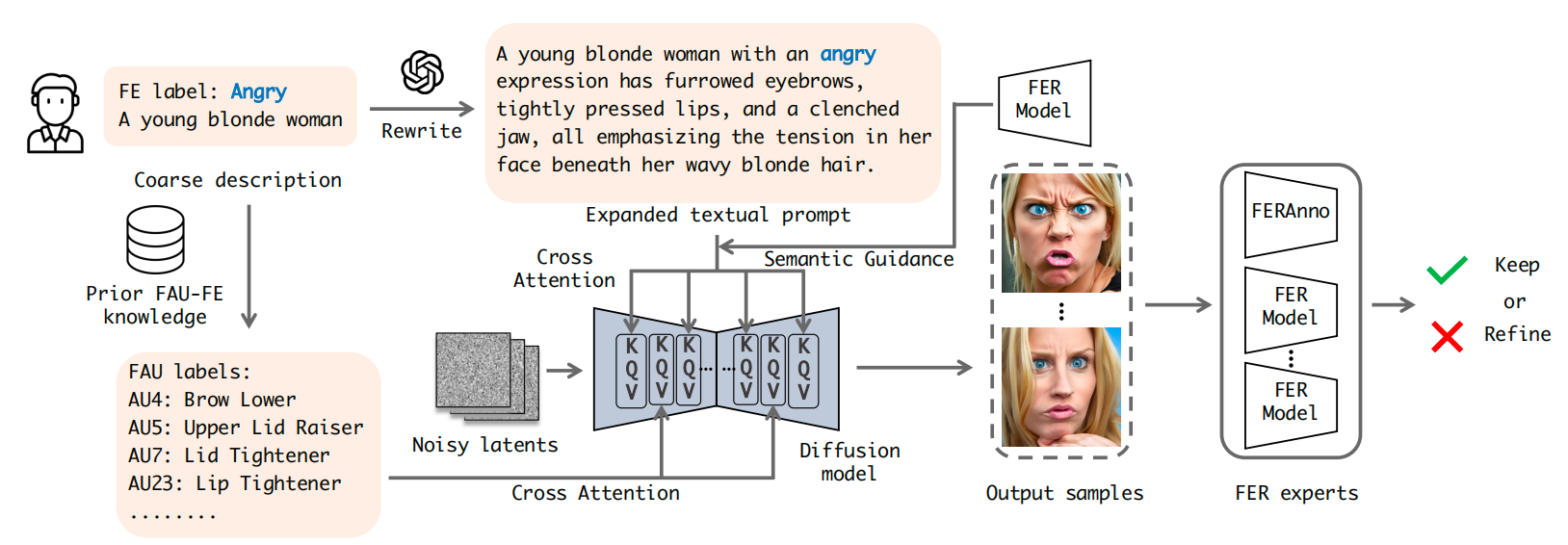
Figure 1: SynFER's FER data synthesis pipeline begins by enriching a coarse textual description and target expression label into a detailed prompt, while simultaneously integrating precise Facial Action Unit (FAU) annotations for fine-grained anatomical control. This multi-modal input conditions a diffusion model, which employs semantic guidance from a pre-trained FER classifier during denoising to ensure high-fidelity expression generation. The resulting images undergo automated label calibration via FERAnno, a diffusion-based validator that analyzes internal features and collaborates with expert models to refine or confirm labels, ultimately producing reliable synthetic data pairs for downstream tasks. This closed-loop process effectively combines high-level semantics, low-level muscle controls, and self-consistency checks to address data scarcity in facial expression recognition.
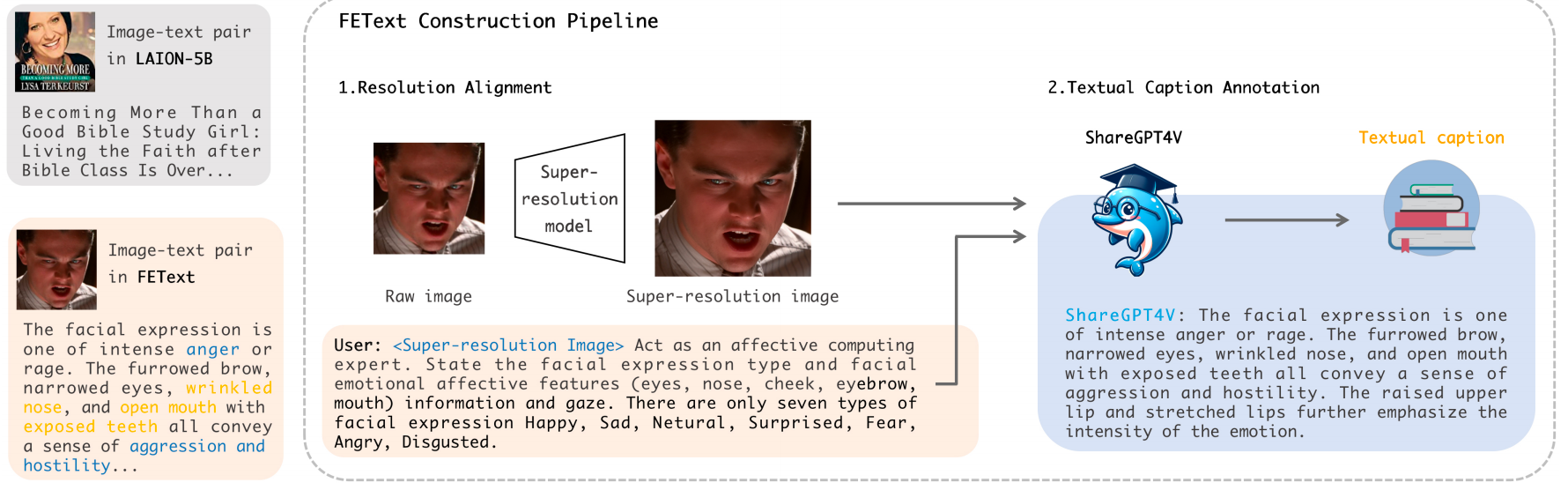
Figure 2: The FEText dataset is constructed through a streamlined, two-stage pipeline to create the first large-scale image-text pairs specifically tailored for facial expression analysis. This process begins by standardizing diverse facial images to high resolution using super-resolution techniques, ensuring visual quality and consistency. Each enhanced image is then processed by the multimodal model ShareGPT-4V, which is specifically instructed to generate detailed, emotion-focused captions that describe the facial expression and its constituent features, resulting in high-quality, expression-centric image-text pairs that provide a crucial semantic foundation for training controllable facial expression generation models.
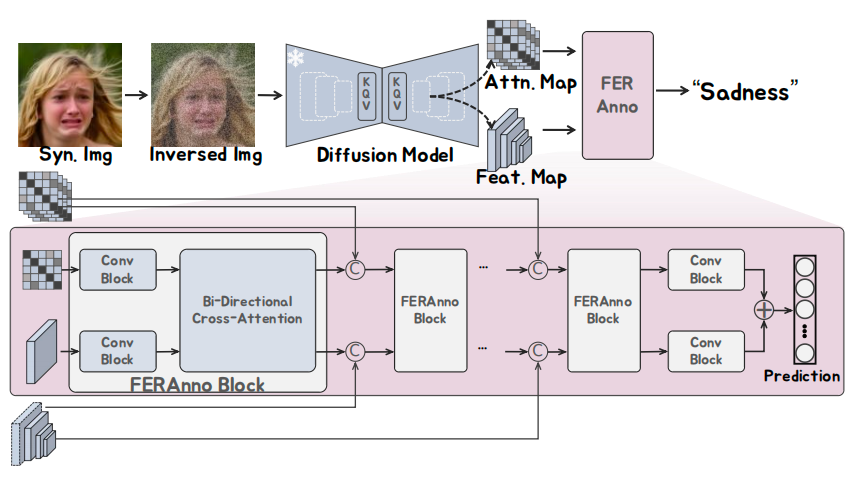
Figure 3: FERAnno operates by first inverting a synthetic facial image back into the latent space of the pre-trained diffusion model. It then extracts multi-scale feature maps and cross-attention maps from the denoising process, which capture rich semantic and structural information about the facial expression. These features are processed through a cascade of specialized FERAnno blocks, each integrating convolutional layers and bidirectional cross-attention mechanisms, to progressively refine the representation, ultimately outputting a calibrated expression prediction such as "Sadness" with high confidence, thereby ensuring the reliability of synthetic data labels.

Figure 4: This figure demonstrates the progressive improvement in generated facial expression quality by incrementally integrating SynFER's core components. Starting with the baseline Stable Diffusion, adding the specialized FEText dataset enhances overall semantic alignment with the target expression. The subsequent integration of FAUs injects precise, fine-grained anatomical control over facial muscle movements, making key features like nose wrinkling in disgust or brow raising in fear more accurate. Finally, the Semantic Guidance (SG) mechanism further refines the output by aligning the global expression semantics, resulting in the most vivid, intense, and authentic-looking expressions in the rightmost column.
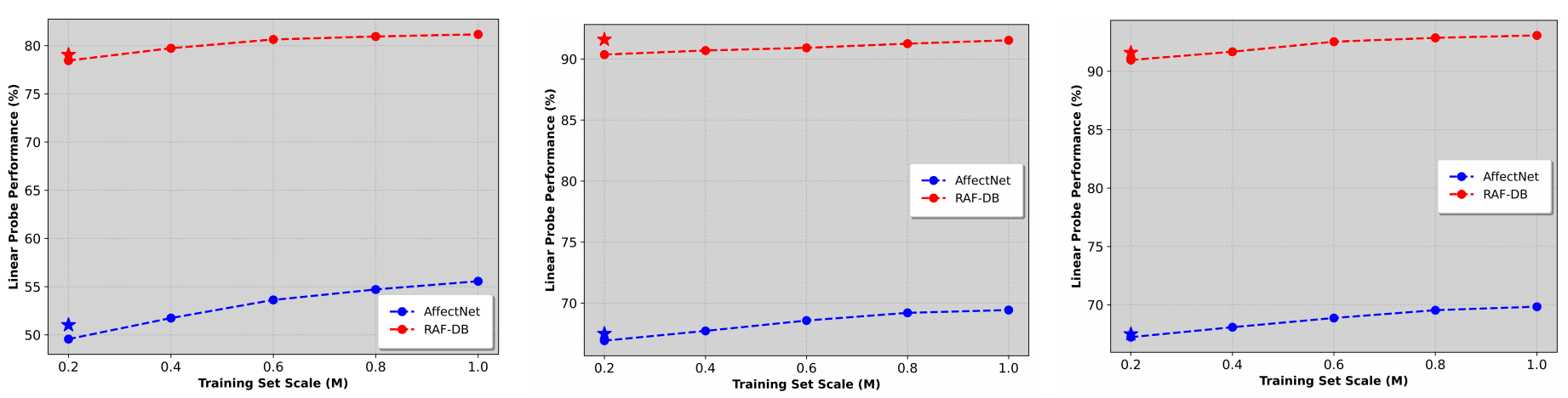
Figure 5: The positive scaling effect of synthetic data on model performance across different learning paradigms: in both self-supervised (a) and supervised learning (b), the linear probe accuracy on AffectNet and RAF-DB consistently improves as the synthetic dataset size increases. Moreover, applying a Real-Fake alignment technique (c) further closes the performance gap, enabling models trained on sufficiently large synthetic data to match or even surpass the accuracy achieved with corresponding real data (indicated by ★).
Acknowledgement
The work was supported by the National Natural Science Foundation of China under grants no. 62276170, 82261138629, 62306061, the Science and Technology Project of Guangdong Province under grants no. 2023A1515010688, the Science and Technology Innovation Commission of Shenzhen under grant no. JCYJ20220531101412030, Open Research Fund from Guangdong Laboratory of Artificial Intelligence and Digital Economy (SZ) under Grant No. GML-KF-24-11, and Guangdong Provincial Key Laboratory under grant no. 2023B1212060076. The research reported in this publication was supported by funding from King Abdullah University of Science and Technology - Center of Excellence for Generative AI, under award number 5940.
Bibtex
@inproceedings{he2025synfer,
title={SynFER: Towards boosting facial expression recognition with synthetic data},
author={He, Xilin and Luo, Cheng and Xian, Xiaole and Li, Bing and Khan, Muhammad Haris and Ge, Zongyuan and Xie, Weicheng and Song, Siyang and Shen, Linlin and Ghanem, Bernard and others},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={10184--10195},
year={2025}
}
Downloads