VesMamba: 3D Pulmonary Vessel Segmentation from CT images via Mamba with Structural Perception and Scale-aware Filtering
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Zhipeng Liu1, Guilian Chen1, Zheng Jiang1, Huisi Wu1*, Jing Qin2
1Shenzhen University
2The Hong Kong Polytechnic University
Abstract
Automated 3D pulmonary vessel segmentation from CT images is crucial for improving early screening and assessment of pulmonary vessel related diseases. However, it remains an extremely challenging task due to the complex and tree-like structures of vessels, large scale-variations, and the existence of highly similar tissues in the background. Existing segmentation models either cannot sufficiently capture long-range structural dependencies, which are of great importance in vessel segmentation, or are constrained by insufficient computational resources in clinical settings. In this paper, we propose VesMamba, a novel model for 3D pulmonary vessel segmentation that comprehensively addresses these challenges. Specifically, we first devise a spatial-gated structural perception (SSP) module, which employs Mamba to efficiently capture long-range dependencies. In SSP, we design dynamic spatial attention convolutions (DSAC) for dynamically learning the tree-like 3D vessel structures, providing Mamba with the spatial perception capability to better track the complicated topologies of vessels. Second, we propose an innovative bidirectional scale-aware filter (BSF) module to strengthen the representation capability of the encoder, facilitating our model to focus on vessels of different scales under noise. Moreover, we apply a mask-constrained decoder to further improve segmentation consistency and accuracy, which constrains the inference of adjacent low-layer decoders directly by high-layer masks. Extensive experiments on the public Parse22 and internal Lung79 datasets demonstrate that our method can achieve better performance than SOTAs.
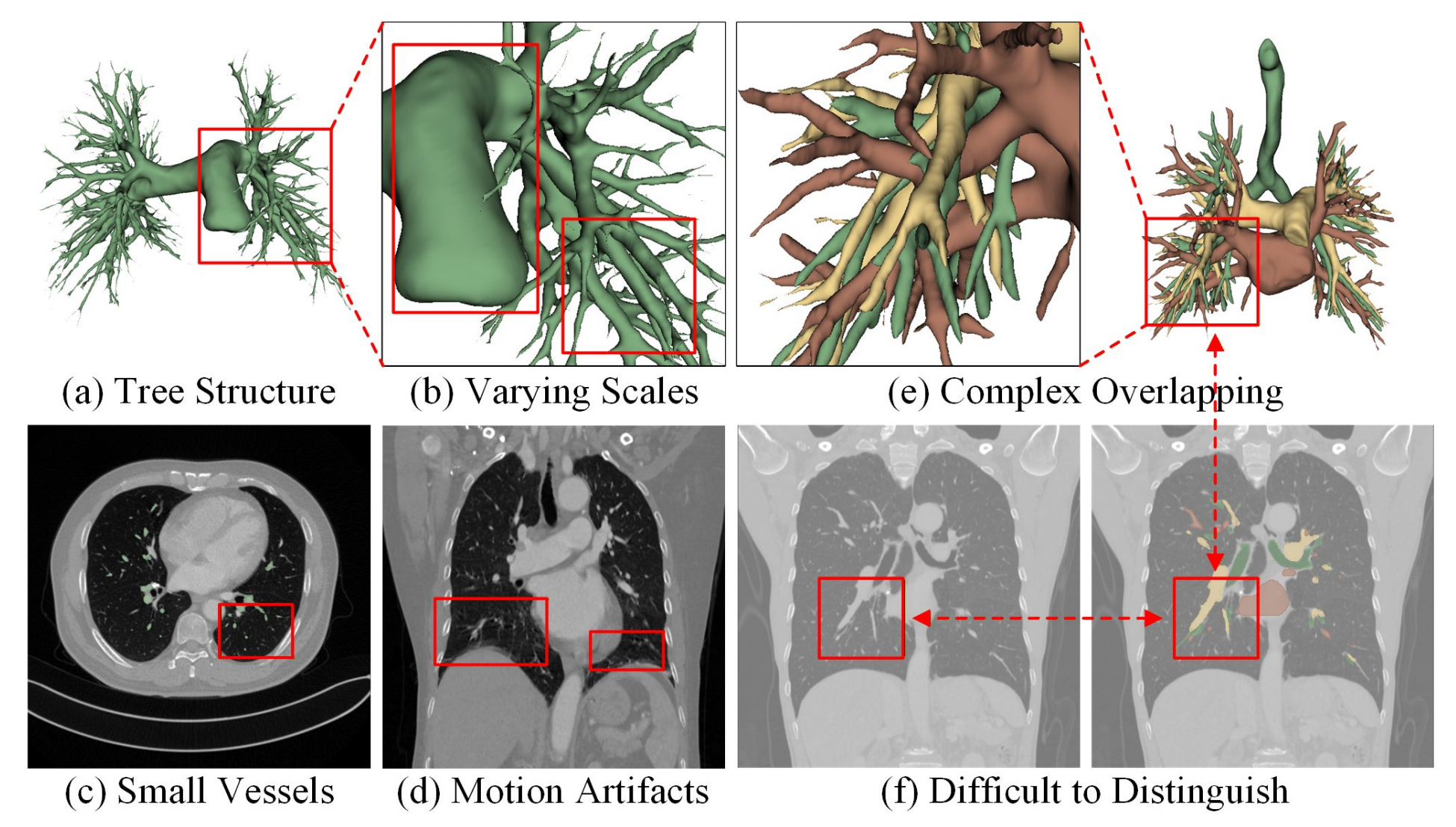
Figure 1: Challenges in 3D pulmonary vessel segmentation: (a) complex tree-like anatomical structure, (b) large variation in scales, (c) small vessels with low contrast, (d) motion artifacts in CT images, (e) complex overlapping, and (f) high similarity between artery and vein.
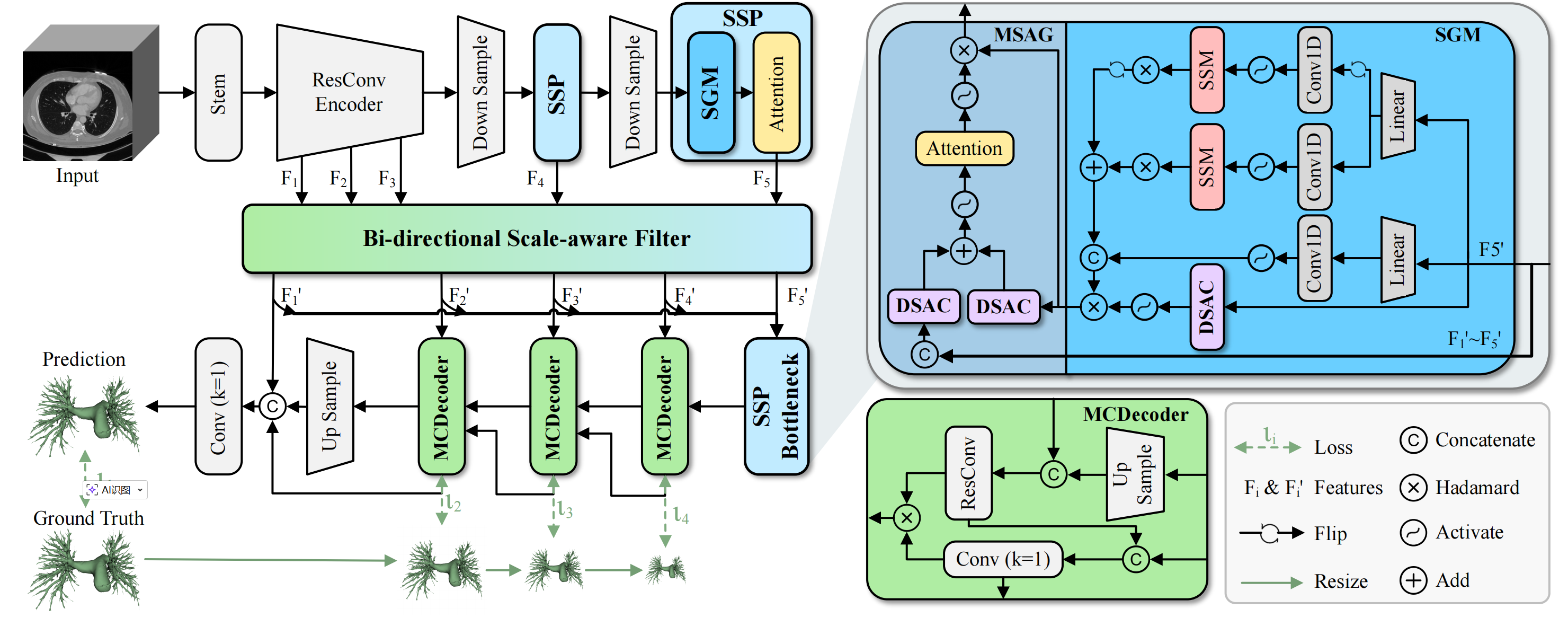
Figure 2: Overview of VesMamba, which primarily consists of two innovative modules: spatial-gated structural perception (SSP) module and bidirectional scale-aware filter (BSF) module. SSP is composed of a spatial gate mamba (SGM) and a self-attention mechanism, enabling efficient feature extraction with spatial perception. BSF fuses encoder features of each layer and filters out noise at different scales from the encoder features to obtain more robust feature representations. Additionally, a mask-constrained decoder (MCDecoder) directly constrains the adjacent low-layer predictions inference by using contour and position information in the high-layer masks, further improving the segmentation consistency and accuracy.
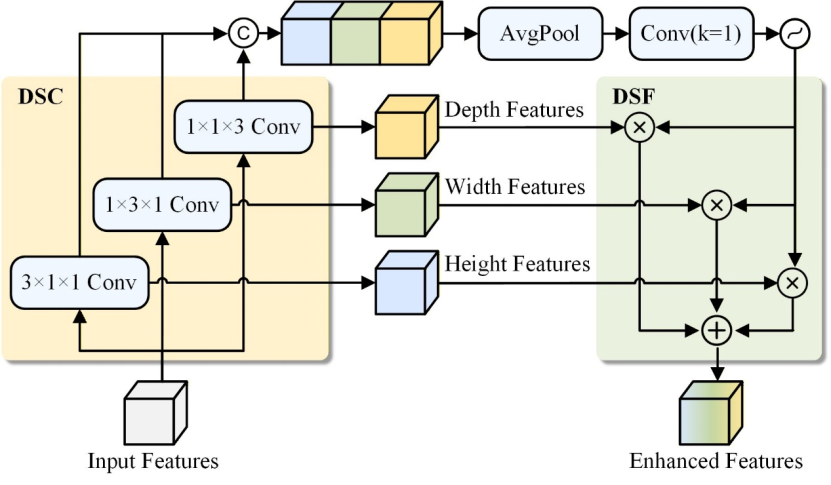
Figure 3: Illustration of DSAC, which consists of directional separation convolution (DSC) and dynamic spatial fusion (DSF).
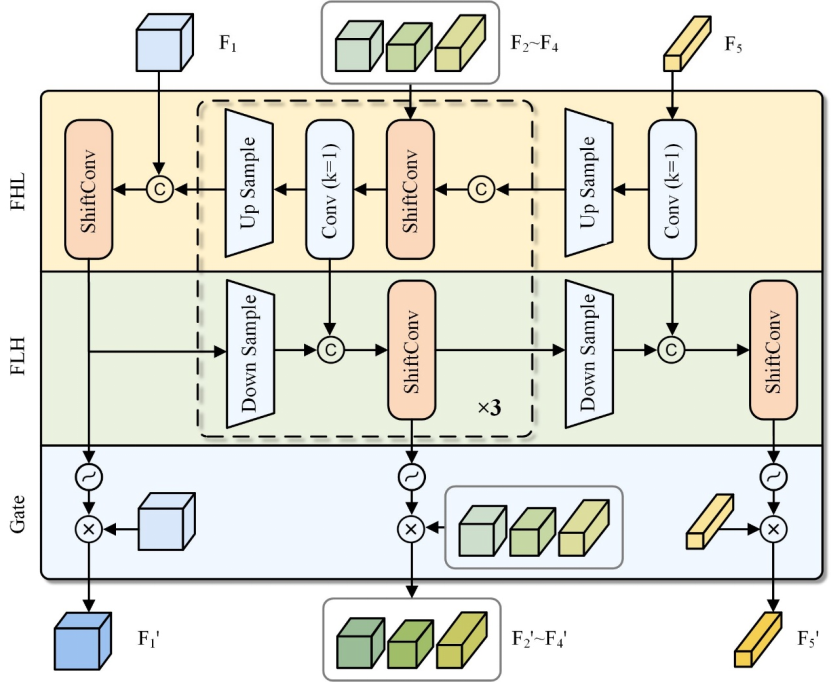
Figure 4: Illustration of BSF. ShiftConv is Depth-shift convolution. FHL denotes high-to-low layer fusion, while FLH is low-to-high layer fusion.
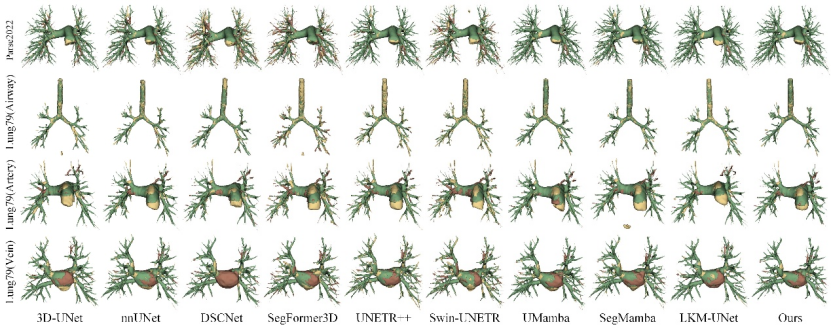
Figure 5: Visual comparison of challenging cases with state-of-the-art methods on the Parse22 and Lung79 datasets. Green, yellow, and red represent true positives, false positives, and false negatives, respectively.
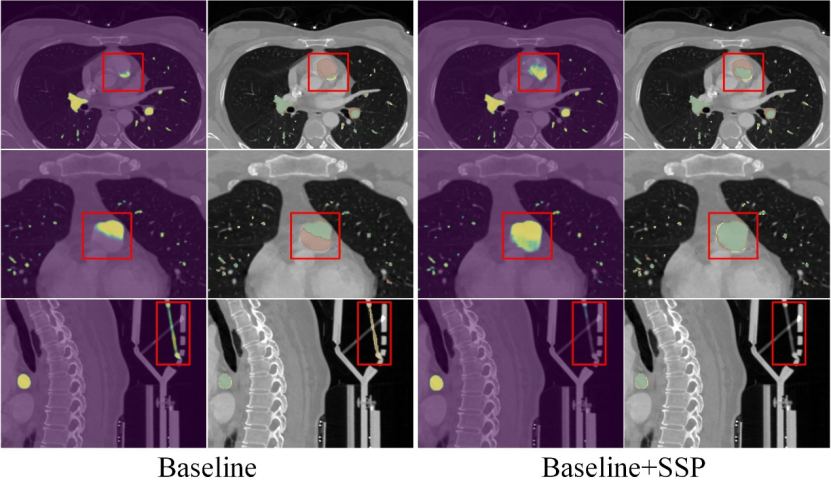
Figure 6: Visual comparison of the results of the SSP module ablation study on Parse22 dataset. Green, yellow, and red represent true positives, false positives, and false negatives, respectively.
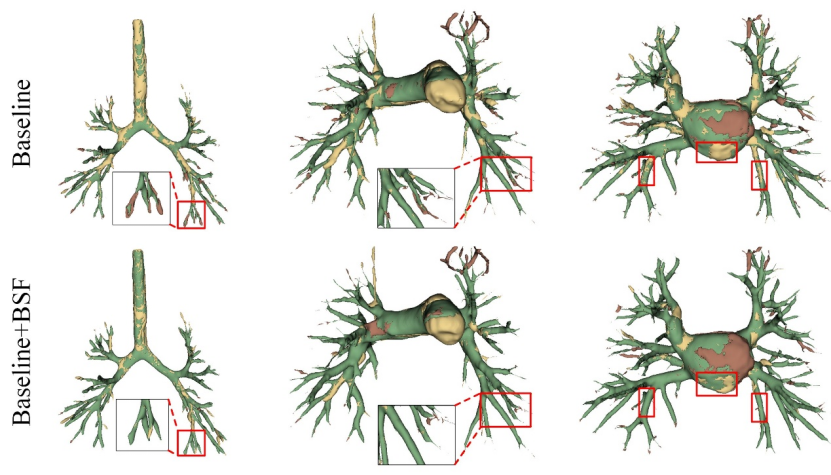
Figure 7: Visual comparison of the results of the BSF module ablation study on Lung79 dataset. Green, yellow, and red represent true positives, false positives, and false negatives, respectively.
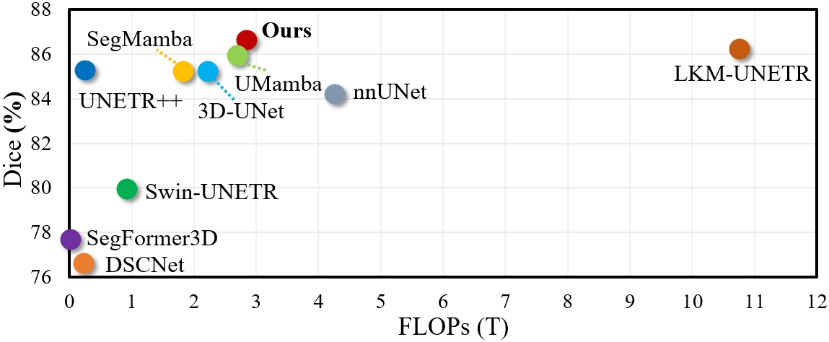
Figure 8: Performance-efficiency comparison with other state-of-the-art methods on Parse22.
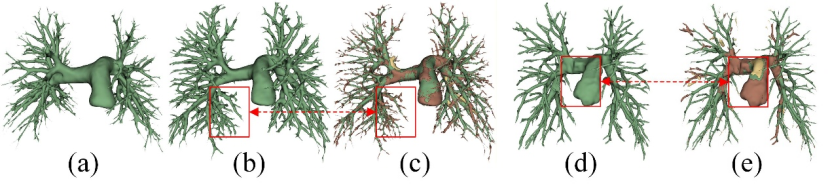
Figure 9: Failure cases. Green, yellow, and red represent true positives, false positives, and false negatives, respectively.
Acknowledgement
This work was supported partly by National Natural Science Foundation of China (No. 62273241), Natural Science Foundation of Guangdong Province, China (No. 2024A1515011946), the Shenzhen Research Foundation for Basic Research, China (No. JCYJ20250604181940054), and the grant of Innovation and Technology Fund under Innovation and Technology Support Programme (project no ITS/202/23).
Downloads