FLIP-80M: 80 Million Visual-Linguistic Pairs for Facial Language-Image Pre-Training
ACM Multimedia (ACM MM)
Yudong Li1, Xianxu Hou2, Dezhi Zheng1, Linlin Shen1*, Zhe Zhao3
1Shenzhen University
2Xi’an Jiaotong-Liverpool University
3Tencnet AI Lab
Abstract
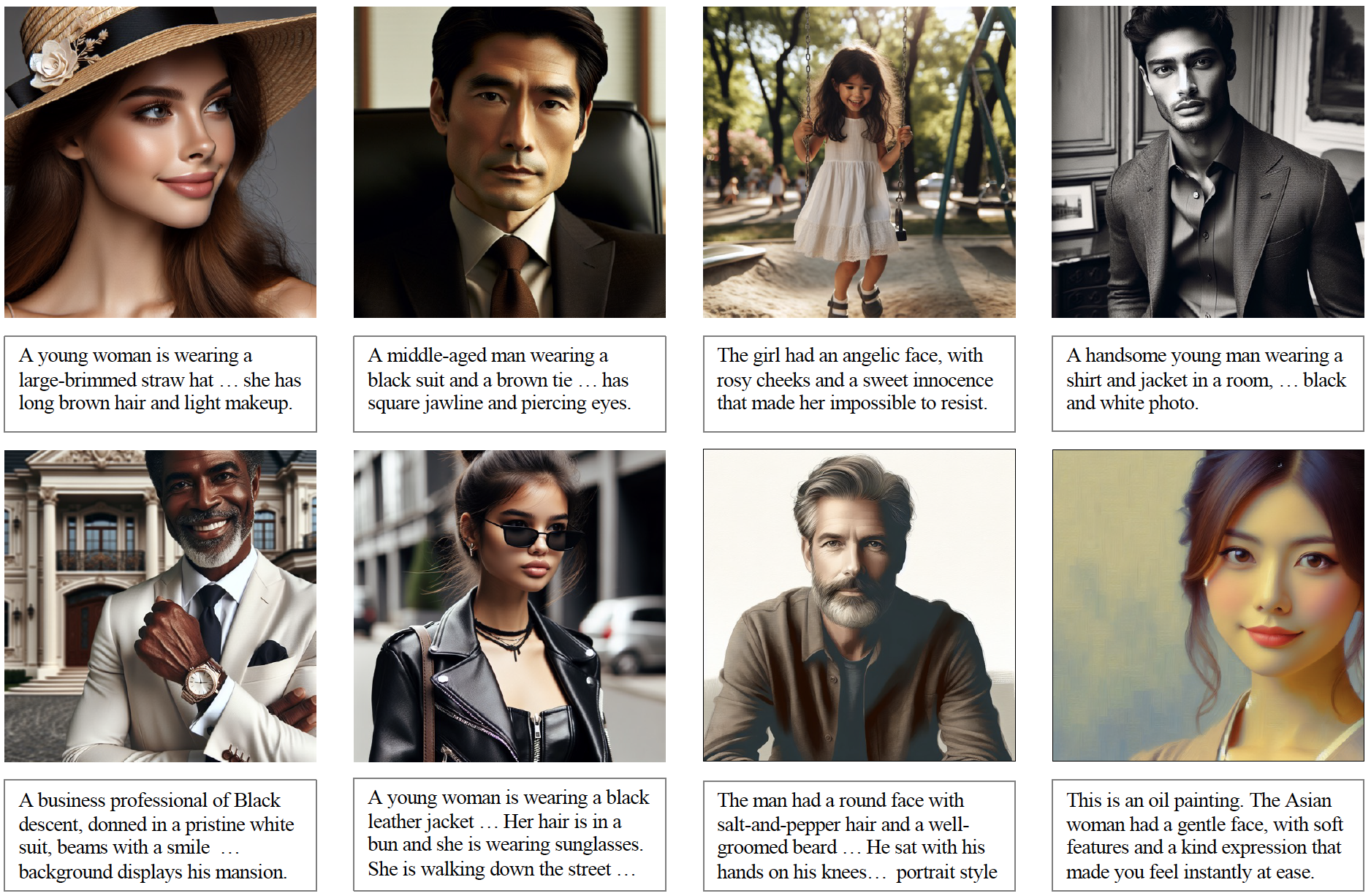
While significant progress has been made in multi-modal learning driven by large-scale image-text datasets, there is still a noticeable gap in the availability of such datasets within the facial domain. To facilitate and advance the field of facial representation learning, we present FLIP-80M, a large-scale visual-linguistic dataset comprising over 80 million face images paired with text descriptions. FLIP-80M is constructed by leveraging the large openly available image-text-pair dataset LAION-5B and a mixed-method approach to filter face-related pairs from both visual and linguistic perspectives. Our curation process involves face detection, face caption classification, text de-noising, and synthesis-based image augmentation. As a result, FLIP-80M stands as the largest face-text dataset to date. To evaluate the potential of our dataset, we fine-tune the CLIP model using the proposed FLIP-80M, to create FLIP (Facial Language-Image Pretraining) and assess its representation capabilities across various downstream tasks. Our experiments demonstrate that our FLIP model achieves state-of-the-art results in a range of face analysis tasks, including face parsing, face alignment, and face attribute classification.
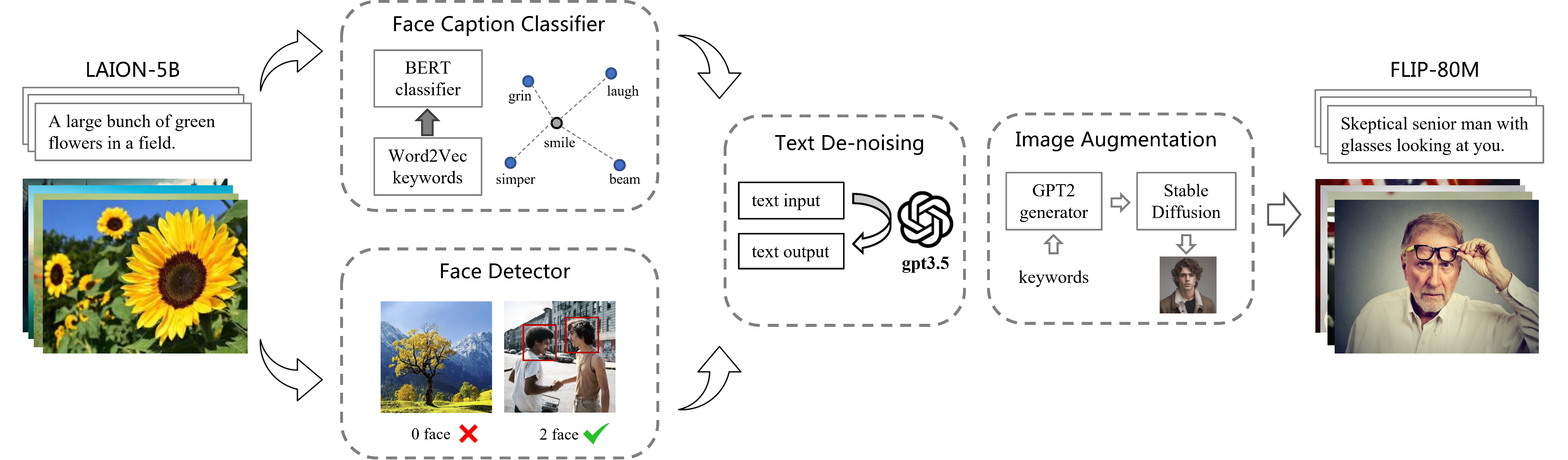
Figure 1: Overview of the FLIP-80M dataset construction pipeline. The original data undergoes several processes, including face detection, face caption classification, text denoising, and AIGC augmentation, resulting in a total of 83 million face-text pairs (including 1 million AIGC samples).
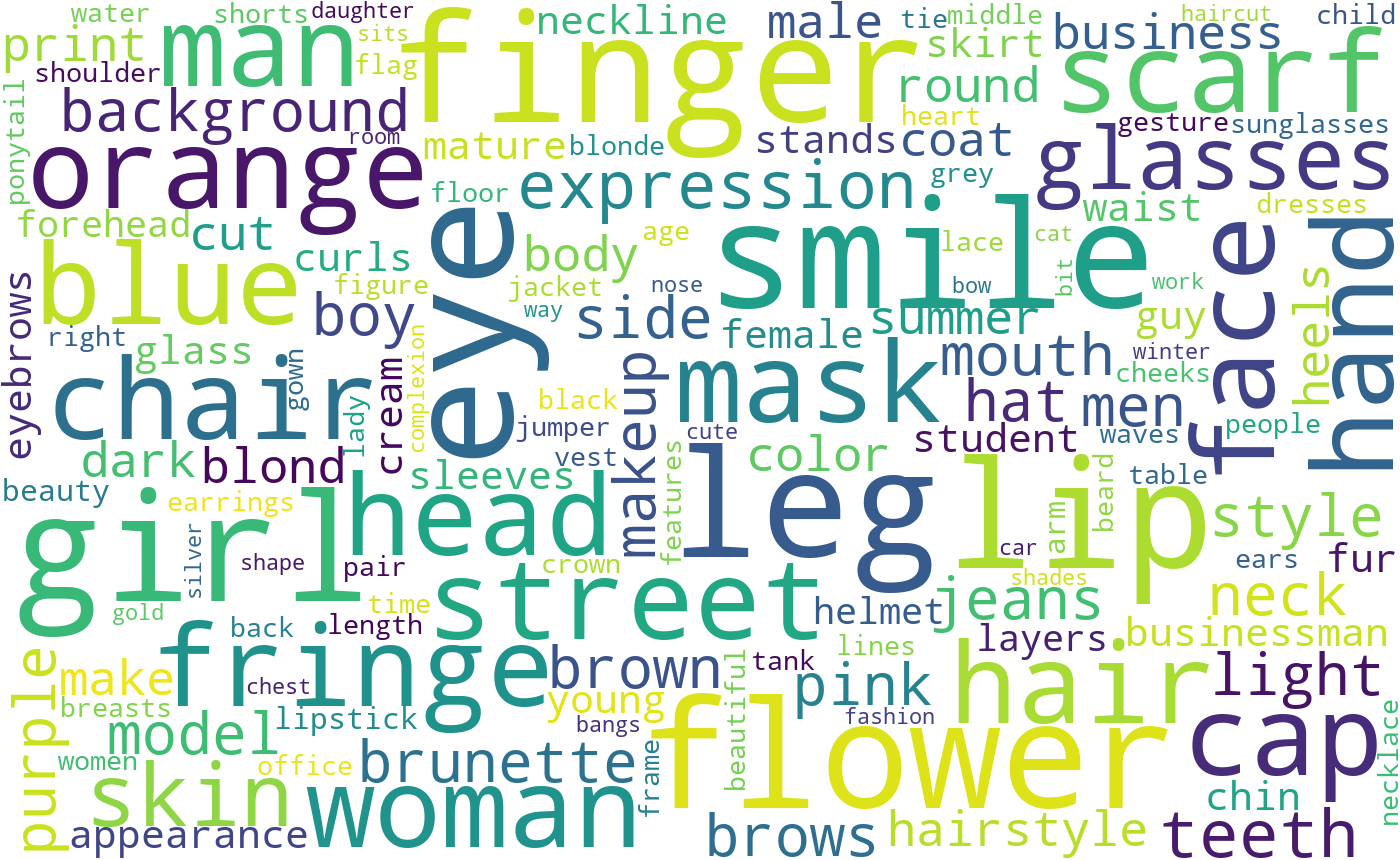
Figure 2: Word cloud of all keywords used for recalling positive samples.
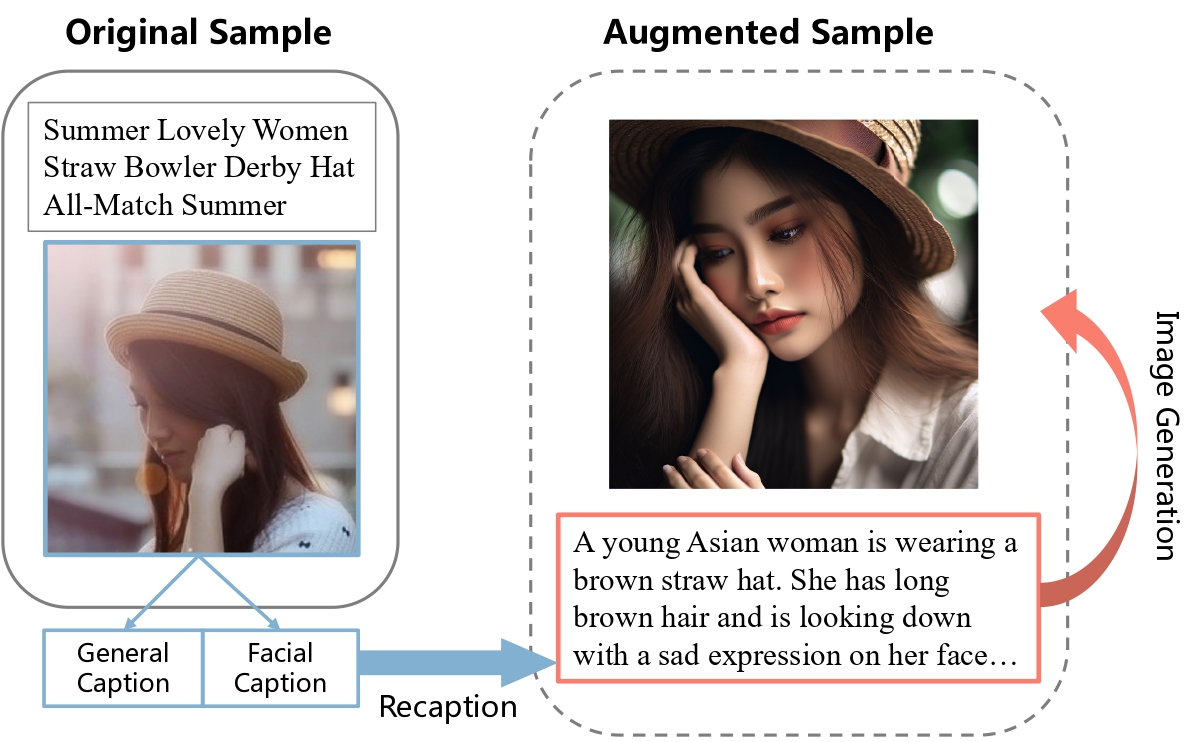
Figure 3: Illustration of the AIGC-based augmentation method. For an original sample, we first recaption the general and facial text descriptions, and then the descriptions are used to generate new image.
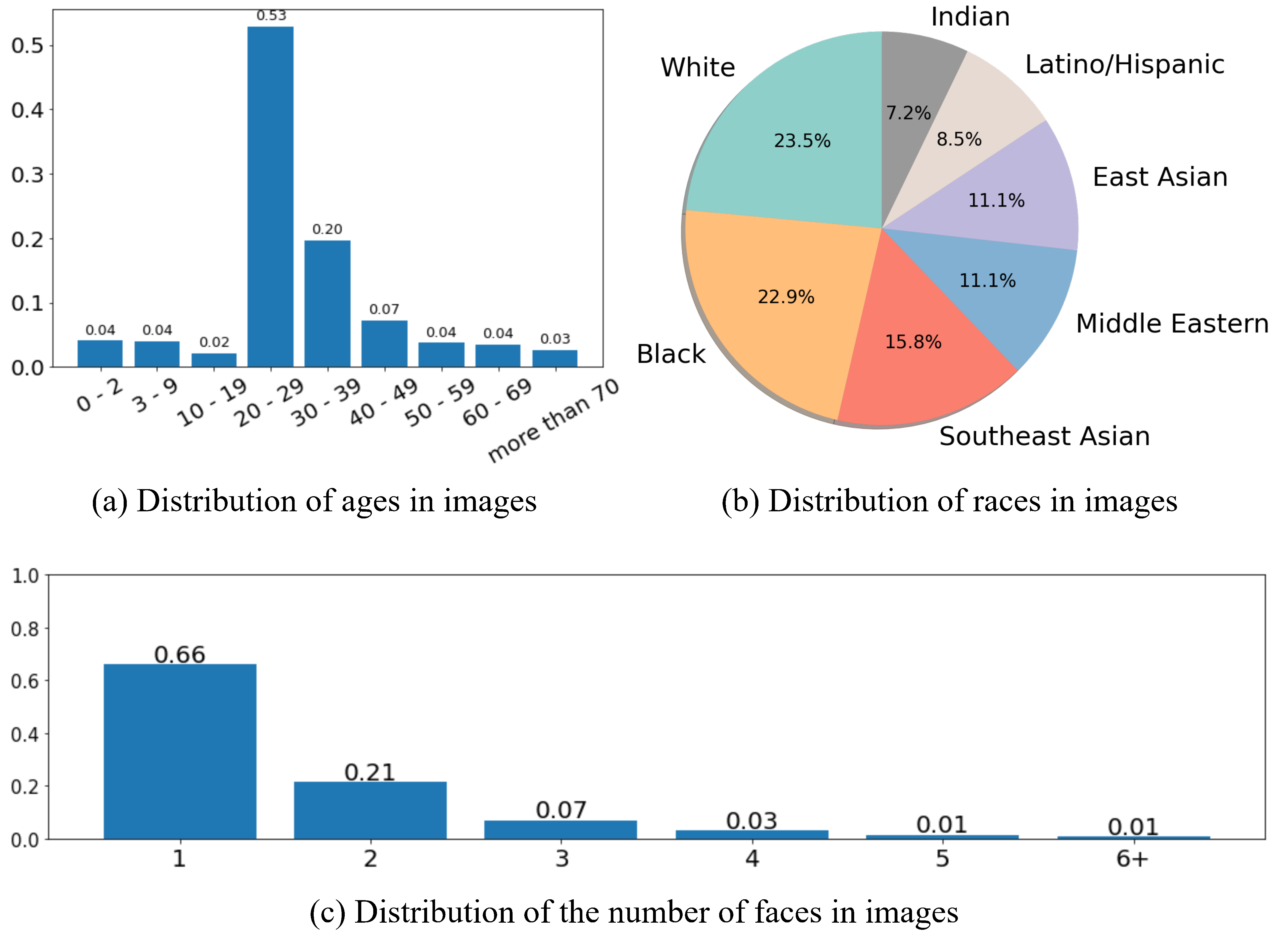
Figure 4: Overview of the statistics for our proposed dataset, detailing distributions across age, race, and the number of faces in images.
Acknowledgement
This work was supported by the National Natural Science Foundation of China under Grant 62206180, 82261138629 and 12326610; Guangdong Basic and Applied Basic Research Foundation under Grant 2023A1515010688 and 2022A1515011018; Shenzhen Municipal Science and Technology Innovation Council under Grant JCYJ20220531101412030; Guangdong Provincial Key Laboratory under Grant 2023B1212060076; XJTLU Research Development Funds under Grant RDF-23-01-053.
Bibtex
@inproceedings{li2024flip,
title={FLIP-80M: 80 Million Visual-Linguistic Pairs for Facial Language-Image Pre-Training},
author={Li, Yudong and Hou, Xianxu and Zheng, Dezhi and Shen, Linlin and Zhao, Zhe},
booktitle={ACM Multimedia 2024}
}
Downloads